| PAGE 2 OF 3 | [1] [2] [ref] | DOWNLOAD PDF |
Reprinted from Proc. Royal Society B 171 179-296
continued
Pictures are the traditional material of perceptual research, but all pictures are highly artificial and present special problems to the perceptual brain. In a sense, all pictures are impossible: they have a double reality. They are seen both as patterns of lines, lying on a flat background and also as objects depicted in a quite different, three-dimensional, space. No actual object can be both two- and three-dimensional and yet pictures come close to it. Viewed as patterns they are seen as two-dimensional; viewed as representing objects they are seen in a quasi three-dimensional space. Pictures lying both in two and in three dimensions are paradoxical visual inputs. Pictures are also ambiguous, for the third dimension is never precisely defined. The Necker cube is an example where the depth ambiguity is so great that the brain never settles for one answer. But any perspective projection could represent an infinity of three dimensional shapes: so one would think that the perceptual system has an impossible task. Fortunately, the world of objects does not have infinite variety; there is usually a best bet, and we generally interpret our flat images more or less correctly in terms of the world of objects. The sheer difficulty of the problem of seeing the third dimension from the two dimensions of a picture - or the retinal images of normal objects - is brought out by special 'impossible pictures' and 'impossible objects', as we shall call them. They show just what happens when clearly incompatible distance information is presented to the eye. The impossible triangle (FIG. 9) (L. S. Penrose and R. Penrose 1958) cannot be seen as an object lying in normal three-dimensional space. It is, however, perfectly possible to make actual three dimensional objects - not mere pictures - which give the same perceptual confusion. Figure 10a shows an actual wooden object which, when viewed from one critical position, gives the same retinal image as the Penrose triangle (Fig. 9). It looks just as impossible - but it really exists. In fact, though one knows all about its true shape (Fig. 10b), it continues to look impossible from the critical viewing position (FIG. 10a).
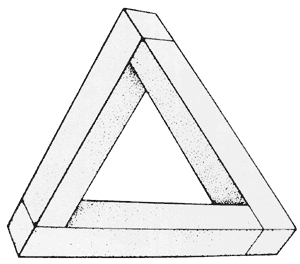
FIG. 9 An impossible figure. This cannot be seen as a sensible three-dimensional figure - no appropriate 'perceptual model' is selected.
 |
 |
FIG. 10 (a) An impossible object. From this critical viewpoint it appears impossible although it exists as a true three-dimensional structure. (b) The same object, but viewed from a non - critical position - the true structure is now evident.
Ordinary pictures are not so very different from obviously 'impossible' pictures. All pictures depicting depth are paradoxical, for we both see them as flat (which they really are) and in a kind of suggested depth which is not quite right. We are not tempted to touch objects depicted in a picture through or in front of its surface. What happens, then, if we remove the background - does the depth paradox of pictures remain?
To remove the background, in our experiments, we make the pictures luminous to glow in the dark. They are viewed with one eye in order to remove stereoscopic information that they are truly flat. They may be wire figures coated in luminous paint, or photographic transparencies back-illuminated with an electro-luminescent panel. In either case there is no visible background, so we can discover how far the background is responsible for the depth paradox of pictures, including the illusion figures. Under these conditions the Müller-Lyer arrows generally look like true corners, according to their perspective. They generally appear indistinguishable from actual (luminous) corners. The figures are, however, not entirely stable; they sometimes reverse spontaneously in depth but generally they appear according to their perspective, and without the paradoxical depth of pictures with a background. The distortions are still present. The outward-going fins figure, looking like an inside corner, is expanded; while the in-going fins figure, looking like an outside corner, is shrunk as before - but now the paradox has disappeared.
The figures look like true corners: one can point out their depth as though they were normal three-dimensional objects.
Having removed the paradox it is possible to measure, by quite direct means, the apparent distances of any selected parts of the figures. This we do by using the two eyes to serve as a rangefinder for indicating the apparent depth of the figure as seen by one eye. The back-illuminated picture is placed behind a sheet of polaroid; one eye being prevented from seeing the picture with a crossed polarizing filter. Both eyes are however allowed to see one FOOTNOTE 1
[There is no 'physical' reason why a luminous object viewed with a single eye should have any assignable distance. In fact even after-images have an apparent distance viewed in darkness (Gregory et al. 1959 [REF 5]). Luminous figures remain at remarkably constant apparent distance, for almost all observers, so that consistent measurements can be made with a single reference light. Presumably a fairly stable 'internal model' is called up, and this settles the apparent distance. This is true also for viewing the moon in a clear sky: it remains remarkably constant in size and distance, until near the horizon when it looks larger and nearer. Perspective and other information then seems to scale the 'model' and so change the size of the moon.]
or more small movable reference lights, which are optically introduced into the picture with a 45° part-reflecting mirror. The distance of these lights is given by stereoscopic vision (convergence angle of the eyes), and so by placing them at the seen distance of selected parts of the picture we can plot the visual space of the observer, in three dimensions. The apparatus is shown in Figure 11. Figure 12 shows the result of measuring depth (difference between the distance of the central line and the ends of the arrow heads) for various fin angles of the Müller Lyer illusion figure. For comparison, the measured illusion for each angle for the same (20) subjects is plotted on the same graph. It is important to note that though the depth was measured with luminous figures, the illusion was measured (using an adjustable comparison line set to apparent equality) with the figures drawn on a normally textured background. So they appeared flat when the illusion was measured but as a true corner when the background was removed for measuring depth. This experiment shows that when the background is removed, depth very closely follows the illusion for the various fin angles. The similarity of these curves provides evidence of a remarkably close tie-up between the illusion as it occurs when depth is not seen with the depth which is seen when the background is removed. This suggests that Thiéry was essentially correct: [Footnote 1] that perspective can somehow produce distortions. But what is odd is that perspective produces the distortion according to indicated perspective depth even when depth is not seen, because it is countermanded by the visible background.
The next step is to look for some perceptual mechanism which could produce this relation between perspective and apparent size. A candidate that should have been obvious many years ago is 'size constancy'. This was clearly described by René Descartes (1596 - 1650), in his Dioptrics of 1637.
'It is not the absolute size of images (in the eyes) that counts. Clearly they are a hundred times bigger (in area) when objects are very close than when they are ten times further away; but they do not make us see the objects a hundred times bigger; on the contrary, they seem almost the same size, at any rate as we are not deceived by too great a distance.'
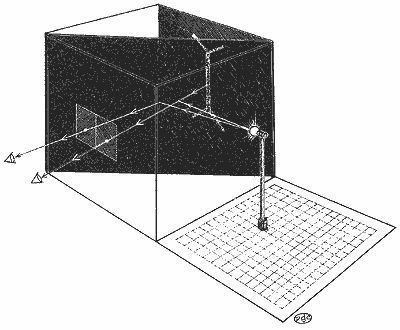
FIG. 11 Pandora's Box. Apparatus for measuring subjective visual depth in pictures. The picture (in this case, an illusion figure) is back-illuminated with an electro - luminescent panel, to avoid background texture. In front of the picture there is a sheet of polaroid and in front of the eyes two sheets of polaroid at right angles; thus the picture can be seen by only one eye. The image of the reference lamp is reflected off a sheet of neutral density Perspex lying diagonally across the box and can be seen with both eyes. The real distance of the lamp, seen binocularly, is matched with the apparent distance of the picture, seen monocularly; and the positions are marked on the graph paper.
We know from many experiments that Descartes is quite correct. But what happens when distance information, such as perspective, is present when there is no actual difference in distance to shrink the image in the eye? Could it be that perspective presented on a flat plane sets the brain's compensation for the normal shrinking of the images with distance - though in pictures there is no shrinking to compensate? If this happened, illusions must be given by perspective. We would then have the start of a reasonable theory of distortion illusions. Features indicated as distant would be expanded; which is just what we find, at least for the Müller-Lyer and the Ponzo figures.
It is likely that this approach to the problem was not developed until recently because although size constancy was very well known, it has always been assumed that it follows apparent distance in all circumstances. Also, it has not been sufficiently realized how very odd pictures are as visual inputs; but they are highly atypical and should be studied as a very special case, being both paradoxical and ambiguous.
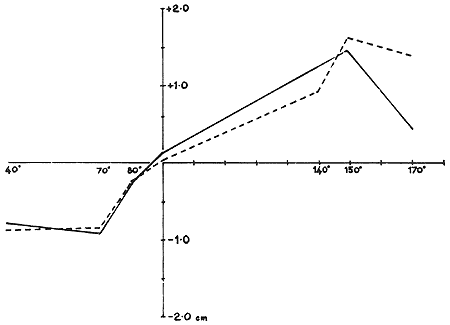
FIG. 12 Müller-Lyer illusion and apparent depth, for various fin angles. The x axis represents the angle between the shaft and fins in the Müller-Lyer figure. (With fins at 90? the figure is a capital I, giving zero illusion and zero depth.) For angles greater than 90? the illusion is positive, for smaller angles negative. The illusion is measured by adjusting a line to the same apparent length for each angle of the illusion figure. The illusion is shown in the dotted line. It was presented on a normally textured background.
The same observers were used to measure apparent depth for the same angles; the illusion being presented without background texture and monocularly to avoid competing depth information. The results in both cases are the means of three readings for each of twenty observers in all conditions. The figure was ten centimetres in length viewed from half a metre. Depth was measured with the 'Pandora's Box' technique, the comparison light being set to the apparent distance of the shaft and the ends of the fins. Depth shown in the solid line.
The correlation between apparent depth and the length distortion is better than 0.9 (experiment by R. L. Gregory and Linda Townes, at M.I.T.).
'Size constancy' is traditionally identified with Emmert's Law, as illustrated by the apparent size of after-images. An after-image (preferably from an electronic flash) is 'projected' upon screens or walls lying at various distances. The after-image will appear almost twice as large with each doubling of distance, though the size of the retinal image from the flash of course remains constant. It is important to note, however, that there is a change in retinal stimulation for each wall or screen lying at a different distance, for their images will be different. It is therefore possible that Emmert's Law is due merely to the relative areas covered by the after-image and the screen, and not to visual information of distance changing the size of the after-image by internal scaling. This presents an experimental problem, which it is vital to solve.
There is a simple solution. We can use the ambiguous depth phenomenon of the Necker cube to establish whether Emmert's Law is due to central scaling by the brain, or is merely an effect of relative areas of stimulation of the retina by after-image and background. When we see a Necker cube drawn on paper reverse in depth, there is no appreciable size change. When presented on a textured background it lies in the paradoxical depth of all pictures with backgrounds. It does not change in size when it reverses in this quasi-depth. What happens, though, if we remove the background? The effect is dramatic, and entirely repeatable: whichever face appears most distant always appears the larger. The use of depth-ambiguous figures allows us to distinguish between what happens as a result of central brain size scaling mechanisms from what happens when the pattern of stimulation of the retina is changed. The answer is that at least part of 'size constancy', and of Emmert's Law, is due to a central size scaling mechanism following apparent distance, though the retinal stimulation is unchanged. But this is not the whole story.
Size is evidently set in two ways. (1) It can be set purely by apparent distance, but (2) it can also be set directly by visual depth features, such as perspective, even though depth is not seen because it is countermanded by the competing depth information of a visible background. When atypical depth features are present, size scaling is set inappropriately; to give a corresponding distortion illusion.
The size scaling set directly by depth features (giving systematic distortions when set inappropriately) we may call 'depth cue scaling'. It is remarkably consistent, and independent of the observer's perceptual 'set'. The other system is very different, being but indirectly related to the prevailing retinal information. It is evidently linked to the interpretation of the retinal image in terms of what object it represents. When it appears as a different object, the scaling changes at once to suit the alternative object. If we regard the seeing of an object as a hypothesis suggested (but never strictly proved) by the image, then we may call this system 'depth hypothesis scaling'.
It changes with each change of hypothesis of what object is represented by the image. When the hypothesis is wrong we have an illusion, which may be dramatic.
We started by pointing out that visual perception must involve 'reading' from retinal images characteristics of objects not represented directly by the images in the eyes. Non-visual characteristics must already have been associated, by individual learning or through heredity, for objects to be recognized from their images. Illusions associated with misplaced size scaling provide evidence that features are selected for scaling according to early perceptual experience of the individual. This is suggested by anthropological data (Segall et al. 1966) and perhaps from the almost total absence of these illusions found in a case of adult recovery from infant blindness (Gregory and Wallace 1963)[REF 1, p. 117, also on this site]. [Footnote 2]
Perception seems, then, to be a matter of 'looking up' stored information of objects, and how they behave in various situations. Such systems have great advantages.
We also use shadow projections for measuring perceptual constancy, especially during movement, as this allows null measures (Anstis, Shopland and Gregory, 1961 [REF 6]).
Systems which control their output directly from currently available input information have serious limitations. In biological terms, these would be essentially reflex systems. Some of the advantages of using input information to select stored data for controlling behaviour, in situations which are not unique to the system, are as follows:
1. In typical situations they can achieve high performance with limited information transmission rate. It is estimated that human transmission rate is only about 15 bits/second (Miller, Bruner and Postman, 1954). They gain results because perception of objects - which are redundant - requires identification of only certain key features of each object.
2. They are essentially predictive. In typical circumstances, reaction-time is cut to zero.
3. They can continue to function in the temporary absence of input; this increases reliability and allows trial selection of alternative inputs.
4. They can function appropriately to object-characteristics which are not signalled directly to the sensory system. This is generally true of vision, for the image is trivial unless used to 'read' non-optical characteristics of objects.
5. They give effective gain in signal/noise ratio, since not all aspects of the model have to be separately selected on the available data, when the model has redundancy. Provided the model is appropriate, very little input information can serve to give adequate perception and control.
There is, however, one disadvantage of 'internal model' look-up systems, which appears inevitably when the selected stored data are out of date or otherwise inappropriate. We may with some confidence attribute perceptual illusions to selection of an inappropriate model, or to mis-scaling of the most appropriate available model.
Selecting and scaling of models, and the illusions
The models must, to be reasonably economical, represent average or typical situations. There could hardly be a separate stored model for every position and orientation an object might occupy in surrounding space. It would be economical to store typical characteristics of objects and use current information to adjust the selected model to fit the prevailing situation. If this idea is correct, we can understand the nature of our 'depth cue' scaling - and why perspective features presented on a flat plane give the observed distortions. Inappropriate depth cues will scale the model inappropriately; to give a corresponding size distortion. This, I suggest, is the origin of the distortion illusions. They occur whenever a model is inappropriately scaled.
There will also be errors, possibly gross errors, when a wrong model is selected - mistaking an object for something very different, confusing a shadow with an object, seeing 'faces-in-the-fire', or even flying saucers. Each model seems to have a typical size associated with it, so mis-selection can appear as a size error. This occurs in the case of the luminous cubes, which change shape with each reversal though the sensory input is unchanged.
If this general account of perception as a 'look-up' system is correct, we should expect illusions to occur in any effective perceptual system faced with the same kind of problems. The illusions, on this theory, are not due to contingent limitations of the brain, but result from the necessarily imperfect solution adopted to the problem of reading from images information not directly present in the image. In considering the significance of experimental data and phenomena for understanding brain function, it seems very important to distinguish between effects which depend on the particular, contingent, characteristics of the brain and the much more general characteristics of any conceivable system faced with the same kinds of problem. Non-contingent characteristics can be regarded in terms of logical and engineering principles, and engineering criteria of efficiency can be employed (cf. Gregory, 1962 a [REF 8]) to help decide between possible systems.
I have distinguished between: (a) selecting models according to sensory information, and (b) size-scaling models to fit the orientation and distance of external objects. I have also suggested that errors in either selecting or scaling give corresponding illusions. These systematic illusions are regarded as non-contingent, resulting from the basic limitations of the system adopted - probably the best available - by brains to solve the perceptual problem of reading reality from images. We should thus expect to find similar illusions in efficiently designed 'seeing machines' (Gregory 1967c).
Now let us consider an experimental situation designed to tell us something about the 'engineering' nature of brain models. We make use of the size/weight illusion, mentioned above, but we look for a change in discrimination as a function of scale distortion of weight.
Consider the following paradigm experiment. We have two sets of weights, such as tins filled with lead shot. Each set consists of say seven tins all of a certain size, while the other set has seven tins each of which is, say, twice the volume of the first set. Each set has a tin of weight, in grams, 85, 90, 95, 100, 105, 110, 115. The 100 gm. weight in each set is the standard, and the task is to compare the other weights in the same set with this standard, and try to distinguish them as heavier or lighter. (The tins are fitted with the same-sized handles for lifting, to keep the touch inputs constant except for weight). Is discrimination the same for the set of apparently heavier weights, which are in fact the same weights? The answer is that discrimination is worse for weights either apparently heavier or lighter than weights having a specific gravity of about one (Ross and Gregory 1970 [REF 2]). why should this be so?
Suppose that sensory data are compared with the current internal model - as they must be to be useful. Now if the data are not only compared with it, but balanced against it, then we derive further advantages of employing internal models. We then have systems like Wheatstone bridges, and these have useful properties. Bridge circuits are especially good (a) over a very large input intensity range and (b) with components subject to drift. Now it is striking how large an intensity range sensory systems cover (1:105 or even 1:106), and the biological components are subject to far more drift than would be tolerated by engineers in our technology confronted with similar problems. Balanced bridge circuits seem a good engineering choice in the biological situation.
Consider a Wheatstone bridge in which the input signals provide one arm and the prevailing internal model the opposed arms against which the inputs are balanced. Now the internal arms are parts of the model - and will be set inappropriately in a scale-distortion illusion. In the size weight illusion, visual information may be supposed to set a weight arm incorrectly. An engineer's bridge will give impaired discrimination either when the bridge is not balanced or when the ratio arms are not equal. The biological system gives just what a practical engineer's bridge would give - loss of discrimination associated with an error in balancing the bridge. This is perhaps some evidence that internal models form arms of bridge circuits. (There is no evidence for suggesting whether scale-distortion illusions result from unequal ratio arms or from imbalance of the supposed bridges. We propose to do further work, experimental and theoretical, to clear up this point).
Are brain models digital or analogue? It is possible to make an informed guess as to which system is adopted by the brain; in terms of speed of operation, types of errors and other characteristics typical of analogue or digital engineering systems (cf. Gregory, 1953b [REF 7]). The engineering distinction arises from the fact that in practice analogue systems work continuously but digital systems work in precisely defined discrete steps. This difference is immensely important to the kinds of circuits or mechanical systems used in practical computers. Discontinuous systems have higher reliability in the presence of 'noise' disturbance while analogue devices can have faster data transmission rates, though their precision is limited to around 0.1%. There is no limit in principle to the number of significant figures obtainable from a digital computer, if it has space enough and time.
Because of the clear engineering distinction between continuous and discontinuous systems, there is a temptation to define analogue in terms of continuous and digital in terms of discontinuous. But this will not do. We can imagine click stops fitted to a slide rule; this would make it discontinuous, but it would still be an analogue device. We must seek some deeper distinction.
The point is that both 'analogue' and 'digital' systems represent things by their internal states. The essential difference between them is not how they represent things, but rather in what they represent. The distinction is between representing events directly by the states of the system, and representing symbolic accounts of real (or hypothetical) events. Real events always occur in a continuum, but symbolic systems are always discontinuous. The continuous discontinuous computer distinction reflects, we may suggest, this difference between representing the world of objects directly and representing symbolic systems. (Even the continuous functions of differential calculus have to be handled as though they were discretely stepped).
A continuous computing device can work without going through the steps of an analytical or mathematical procedure. A digital device, on the other hand, has to work through the steps of an appropriate mathematical or logical system. This means that continuous computers functioning directly from input variables necessarily lack power of analysis, but they can work as fast as the changes in their inputs - and so are ideal for real-time computing systems, provided high accuracy is not required. The perceptual brain must work in real time, and it does not need the accuracy or the analytical power of a digital system, following the symbolic steps of a mathematical treatment of the situation.
It is most implausible to suppose that the brain of a child contains mathematical analyses of physical situations. When a child builds a house of toy bricks, balancing them to make walls and towers, we cannot suppose that the structural problems are solved by employing analytical mathematical techniques, involving concepts such as centre of gravity and coefficient of friction of masses. It is far better to make the lesser claim for children and animals: that they behave appropriately to objects by using analogues of sensed object-properties, without involving mathematical analyses of the properties of objects and their interactions. Perceptual learning surely cannot require the learning of mathematics. It is far more plausible to suppose that it involves the building of quite simple analogues of relevant properties of objects: relevant so far as they concern the behaviour of the animal or the child.
This and other considerations force us to question the traditional distinction between 'analogue' and 'digital'. The discontinuous continuous distinction will not serve. It is a matter of distinguishing between computing systems which solve problems by going through the steps of a formal argument, or mathematical analysis, from systems which solve problems without 'knowing' logic or mathematics - by following the input variables and reading off solutions with a look-up system of internal functions. We need a new terminology for this distinction.
To name the first type of computer, we can go back to Charles Babbage's Analytical Engine, of about 1840. Systems employing formal or mathematical analysis we may call 'Analytical computers'. In practice these will be discontinuous, the steps representing the steps of the analytical argument, or mathematics. But this is not its defining characteristic, which is that it works by following an analysis of the prevailing problem or situation. A convenient term for computers which arrive at solutions by look-up systems of internal syntheses of past data - 'models' reflecting aspects of reality - is more difficult to find. We propose the term: 'Synthetical computers'. It is hoped that these terms - analytical and synthetical computers - may be helpful.
It is reasonable to suppose that the invention of logic and mathematics has conferred much of the power humans have compared with other animals for many kinds of problem solving. We have synthetical brains which use, with the aid of explicit symbols, analytical techniques. It is interesting that even the most advanced analytical techniques are useless for some physical problems - predicting the weather, the tides, economic trends, for example - and then we have to rely on inductively derived models and crude synthetical techniques. Almost always simplifications and corrections have to be used when analytical techniques are applied to the real world; so it is not entirely surprising that synthetical brains are so successful. Indeed, we do not know how to programme an analytical computer to process optical information for performing tasks that would be simple for a child. Surely the child does not do it this way.
The brain must work in real time, but it need not work according to analytical descriptions of the physical world, if all it requires are quite crude synthetical analogues of input - output functions, selected by distinguishing features of objects. The perceptual brain reflects the redundancy of the external world: when it does so correctly we see aspects of reality without illusion. A wrong model - or the right model wrongly scaled - gives corresponding illusions. These can serve as clues to the way sensory information is handled by the brain, to give perception and behaviour.
1. Thiéry's choice of a 'saw-horse' (a horizontal beam supported on legs forming triangles at each end) is a poor example for the legs are not at any specific angle, such as a right angle. He may not have seen that for perspective to serve as a depth cue, reliable assumptions about angles must be possible. The legs of a saw-horse can be at almost any angle; so it is not a good example of depth being given by perspective projection. BACK TO TEXT
2. It seems possible that the curvature distortions
given by radiating background lines (e.g. Hering's and Wundt's
illusions, FIG. 4) should be attributed to mis-scaling from the
spherical perspective of the images on the hemispherical surface
of the retina to the effective linear perspective of perception.
The distortions are in the right direction for such an interpretation,
but precise experiments remain to be completed.
Errors in the prevailing model can be established independently
of the standard distortion illusions, by introducing systematic
movement. Most simply, a point light source is used to cast a
shadow of a slowly rotating (1 rev/min) skeleton object. The projected
shadow, giving a two-dimensional projection of a rotating three-dimensional
object, is observed. It is found that simple familiar objects
will generally be correctly identified, as they rotate. The projections
of unfamiliar objects, and especially random or irregular shapes
will, however, continually change, the angles and lengths of lines
of the projection changing as the object rotates, often appearing
different each time the object comes round to the same position.
By adding stereoscopic information (using a pair of horizontally
separated point sources, cross-polarized to the eyes and a silver
or ground-glass screen to prevent depolarization) we find that,
on this criterion, the correct model is given more readily for
unfamiliar or irregular figures: but stereoscopic information
does not invariably select the correct model (Gregory, 1964b [REF
4]).] BACK TO TEXT
NEXT PAGE CONTAINS REFERENCES ONLY
![]()